명령어 Instruction
- 혼자 공부하는 컴퓨터 구조+운영체제-강민철 책 내용 정리
- 첨부 이미지 출처 : 책
- 풀스택 코드 흐름 적용(LLM 활용)
-
고급언어 : 소스코드
- 사람이 이해하는 언어
-
저급언어 : 목적코드
- 컴퓨터가 직접 이해하고 실행하는 언어
- 기계어 : 0, 1
- 어셈블리어 : 기계어를 읽기 편한 형태로 번역한 언어
- 컴퓨터가 직접 이해하고 실행하는 언어
-
컴파일 언어 - 컴파일러
- 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급언어
- 링킹 - 링커
- 목적파일 : 목적코드로 이루어진 파일
-
인터프리트 언어 - 인터프리터
- 소스 코드가 한 줄씩 실행됨
-
명령어 종류는 CPU마다 다름
명령어 = 연산코드 + 오퍼랜드
연산코드 operation code
- 연산자
- 명령어가 수행할 연산
- 종류
- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
오퍼랜드 operand
- 피연산자
- 연산에 사용할 데이터 = 연산에 사용할 데이터가 저장된 위치
- 데이터를 직접 명시하기보다 ‘위치=주소’ 정보를 표기
- 만약 데이터를 직접 표시한다면,
- 명령어 길이는 고정 → 오퍼랜드 개수에 따라 표현할 수 있는 데이터 크기가 결정됨
- 만약 데이터를 직접 표시한다면,
- 데이터를 직접 명시하기보다 ‘위치=주소’ 정보를 표기
- 메모리 주소 / 레지스터 이름
- 메모리 주소/레지스터 이름 명시한다면,
- 메모리/레지스터 크기만큼 데이터 표현 가능
- 메모리 주소/레지스터 이름 명시한다면,
- 오퍼랜드 개수에 따라
오퍼랜드 개수-주소 명령어
- 유효 주소 effective address : 실 데이터가 저장된 위치
주소 지정 방식 addressing mode
- 유효 주소를 찾는 방법 = 연산에 사용할 데이터 위치를 찾는 방법
- 즉시 주소 지정 방식 immediate addressing mode
- 오퍼랜드 필드에 데이터 직접 명시
- 직접 주소 지정 방식 direct addressing mode
- 오퍼랜드 필드에 유효 주소를 직접 명시
- 명령어에서 연산코드 만큼을 제외한 크기에 유효주소를 표현
- 표현할수 있는 유효 주소에 제한이 생길수 있음…?
- 간접 주소 지정 방식 indirect addressing mode
- 유효주소의 주소를 오퍼랜드 필드에 명시
- 표현할수 있는 유효 주소 범위가 더 넓어짐
- but, 두 번 메모리 접근이 필요함 ⇒ 느림
- 레지스터 주소 지정 방식 register addressing mode
- CPU 외부에 있는 메모리에 접근하는 것 보다 CPU 내부에 있는 레지스터에 접근하는게 더 빠름
- but, 2번 방식과 같은 문제
- 레지스터 간접 주소 지정 방식 register indirect addressing mode
- 연산에 사용할 데이터 : 메모리에 저장 → 이 주소를 레지스터에 저장
- 해당 레지스터를 오퍼랜드 필드에 명시
스택 stack
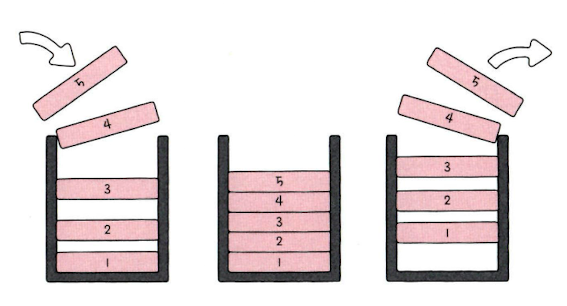
- 후입선출 : LIFO (Last In First Out)
- PUSH / POP
큐 queue
- 선입선출 : FIFO (First In First Out)
✔️ 풀스택 실무에 적용해본다면,
1. 고급언어 - 저급언어
- JS/TS처럼 고급언어로 개발하지만, CPU는 저급언어(기계어) 만 실행할 수 있음 → 고급 언어를 어떻게 기계어(저급 언어)로 변환할까?
1️⃣ 두 가지 해결 방식: 컴파일 vs 인터프리터
| 언어 | 실행방식 | 변환 타이밍 | 장점 | 활용 |
|---|---|---|---|---|
| JavaScript | 인터프리트 + JIT | 실행 중 | 유연함 | web, Node |
| Rust / C++ | AOT 컴파일 | 실행 전 | 빠르고 안정 | 시스템, 서버 성능 작업 |
- AOT : 개발은 불편하지만 실행은 빠름
- 인터프리터 : 개발은 편하지만 실행은 느림 → 해결책 : JIT 컴파일
2️⃣ JIT Just In Time 컴파일
처음엔 인터프리터처럼 빠르게 실행하다가 자주 쓰는 코드만 최적화(골라서 컴파일)
- 프로그램이 시작되면 일단 인터프리터로 실행
- 한 줄씩 해석하면서 실행
- 실행중 자주 호출되는 함수나 반복되는 코드 파악
- 해당 코드를 최적화된 기계어로 컴파일해서 캐싱
- 다음부터는 컴파일된 버전을 직접 실행
- JavaScript V8 엔진이나 SpiderMonkey에서 사용
function add(a, b) {
return a + b;
}
// 처음 몇 번 호출: 인터프리터로 실행 (느림)
add(1, 2);
add(3, 4);
// 반복문에서 1000번 호출
for (let i = 0; i < 1000; i++) {
add(i, i+1); // ← 여기서 "Hot Code" 감지!
}
// JIT이 add() 함수를 기계어로 컴파일 & 캐싱
// 이후 add() 호출은 컴파일된 버전 사용 (빠름)3️⃣ 실제 구현 : V8 엔진(Chrome, Node.js)
V8의 JIT 컴파일 과정
브라우저에서 JavaScript가 실행되는 과정
JavaScript 코드
↓
Parser → AST 추상구문트리 생성
↓
Bytecode(Ignition)
↓
일단 인터프리트 실행
↓ ↘
Hot Code? 아니면 그냥 계속 인터프리트 실행
↓
JIT 컴파일(TurboFan) - 최적화 컴파일러
↓
최적화된 기계어 실행 (캐싱)
↓
(만약 가정이 틀리면 → Deoptimization → 다시 인터프리터로)🔑핵심 포인트 :
- 반복 호출 되는 “Hot Code”만 최적화 → 미리 컴파일
- 예측이 어려운 동적 타입 → 인터프리트 실행 : 최적화 깨지면 deoptimization 발생
왜 이렇게 복잡할까?
- JavaScript는 동적 타입 언어: 변수 타입이 실행 중에 바뀔 수 있음
- 예:
let x = 5; x = "hello";← 숫자였다가 문자열로 변경 - 해결: 실행하면서 타입 정보를 수집하고, 안정적이면 최적화
4️⃣ 브라우저 vs Node.js: 같은 엔진, 다른 환경
- 공통점: 둘 다 V8 엔진 사용
V8 엔진의 역할 (공통)
├─ JavaScript 파싱
├─ JIT 컴파일 (Ignition + TurboFan)
├─ 메모리 관리 (가비지 컬렉션)
└─ 이벤트 루프 관리
- 차이점: 실행 환경과 제공 API
브라우저 = V8 + 웹 환경
Chrome 브라우저 구조
├─ V8 엔진 (JavaScript 실행)
├─ Blink (렌더링 엔진)
│ └─ HTML 파싱 → DOM 트리
│ └─ CSS 파싱 → CSSOM 트리
│ └─ Layout → Paint → Composite
└─ Web APIs
├─ DOM API (document.querySelector)
├─ Fetch API (네트워크 요청)
├─ Web Storage API (localStorage)
└─ Canvas, WebGL 등
Node.js = V8 + 서버 환경
Node.js 구조
├─ V8 엔진 (JavaScript 실행) ← 브라우저와 동일
├─ libuv (이벤트 루프 + 비동기 I/O)
│ └─ 파일 시스템, 네트워크 등 비동기 처리
└─ Node.js APIs
├─ fs (파일 시스템)
├─ http (서버 생성)
├─ path, os, crypto 등
└─ (DOM API 없음!)
왜 V8을 재사용?
- 개발자 경험: 같은 언어(JavaScript)로 프론트엔드 + 백엔드 개발
- 성능: 이미 최적화된 JIT 컴파일러 활용
- 생태계: npm 패키지 공유
5️⃣ 브라우저 렌더링 파이프라인 : JavaScript가 화면에 영향을 주는 과정
Javascript 실행이 렌더링에 미치는 영향
- Case1: DOM 조작
document.getElementById('box').style.width = '200px';- Layout 다시 계산 (Reflow) → Paint → Composite (비용 큼 💰)
- Case2 : 스타일만 변경
document.getElementById('box').style.color = 'red';- Layout 건너뜀 → Paint → Composite (비용 중간)
- Case3 :
transform/opacity사용document.getElementById('box').style.transform = 'traslateX(100px)';- Layout, Paint 모두 건너뜀 → Composite만 (비용 작음 ⚡)
👉 왜 브라우저 렌더링을 이해해야 할까?
- 성능 최적화: 어떤 코드가 비싼지 알 수 있음
- V8 동작 이해: JavaScript 실행이 전체 파이프라인에서 어디에 위치하는지 파악
- Node.js와 비교: 같은 V8이지만 렌더링 파이프라인은 없음 (서버니까)
🎯 전체 정리
-
CPU는 기계어만 이해
└─ 해결: 컴파일러/인터프리터 -
컴파일은 빠르지만 불편, 인터프리터는 편하지만 느림
└─ 해결: JIT 컴파일 (V8 엔진) -
브라우저에만 JavaScript 사용 가능
└─ 해결: V8을 떼어내서 Node.js 만들기 -
JavaScript 실행이 렌더링에 영향
└─ 이해: 브라우저 렌더링 파이프라인 학습
2. 명령어 Opcode + Operand → 연산 줄이기 = 성능 최적화의 핵심
자바스크립트 실행 예시
function add(a, b) {
return a + b;
}
add(2, 3);이렇게 단순한 코드도 내부에서는,
1️⃣ 함수 호출 준비
├─ 새로운 스택 프레임(Stack Frame) 생성
├─ 반환 주소(Return Address) 저장
├─ 매개변수 a, b를 스택에 푸시 (Operand 저장)
└─ 지역 변수를 위한 공간 할당
2️⃣ 함수 실행
├─ LOAD: 스택에서 a 값을 레지스터로 (Operand 로드)
├─ LOAD: 스택에서 b 값을 레지스터로
├─ ADD: 레지스터 값 덧셈 (Opcode 실행)
└─ STORE: 결과를 스택에 저장
3️⃣ 함수 반환
├─ 반환값을 특정 레지스터에 복사
├─ 스택 프레임 정리 (메모리 해제)
└─ 반환 주소로 점프 (호출한 곳으로 돌아감)
⇒ 그래서 재귀를 깊게 사용하면 stack overflow 같은 문제가 발생하는 것
function factorial(n) {
if (n <= 1) return 1;
return n * factorial(n - 1); // 재귀 호출
}
factorial(10000); // Stack Overflow!- stack memory 상황
[메모리 구조]
───────────────
│ factorial(10000) │ ← 스택 프레임 10,000개 쌓임!
│ factorial(9999) │
│ factorial(9998) │
│ ... │
│ factorial(2) │
│ factorial(1) │ ← 여기서 return 시작
───────────────
↑
스택은 크기 제한이 있음 (보통 1~8MB)
너무 깊이 쌓이면 → Stack Overflow 에러
1️⃣ 연산 최적화
Case A : 효율적인 배열 합 구하기
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i]; // 복합 할당 연산자
}CPU 명령어 수준 (간소화) → 4개의 명령어
// sum += arr[i] 의 실제 명령어
LOAD R1, [sum 주소] // 1. sum 값 로드
LOAD R2, [arr + i*8 주소] // 2. arr[i] 값 로드
ADD R3, R1, R2 // 3. R1 + R2
STORE [sum 주소], R3 // 4. 결과 저장Case B : 비효율적인 합 구하기
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum = sum + arr[i]; // 일반 할당
}CPU 명령어 수준 → 5개의 명령어 (LOAD가 한 번 더!)
// sum = sum + arr[i] 의 실제 명령어
LOAD R1, [sum 주소] // 1. sum 값 로드
LOAD R2, [sum 주소] // 2. sum 값 또 로드 (중복!)
LOAD R3, [arr + i*8 주소] // 3. arr[i] 값 로드
ADD R4, R2, R3 // 4. R2 + R3
STORE [sum 주소], R4 // 5. 결과 저장- 대규모 데이터에서는 서버 비용과 직결됨
2️⃣ 최적화의 계층 구조
[레벨 1] 알고리즘 최적화 (O(n²) → O(n log n))
↓ 가장 큰 영향
[레벨 2] 언어 수준 최적화 (sum = sum + x → sum += x)
↓ 중간 영향
[레벨 3] 컴파일러 최적화 (JIT, 인라이닝)
↓ 자동 처리
[레벨 4] 하드웨어 최적화 (CPU 캐시, 파이프라이닝)
↓ CPU가 알아서
개발자가 제어 가능한 부분
✅ 알고리즘 선택
// 나쁨: O(n²)
for (let i = 0; i < arr.length; i++) {
for (let j = 0; j < arr.length; j++) {
// ...
}
}
// 좋음: O(n)
const map = new Map();
for (let item of arr) {
map.set(item.id, item);
}✅ 불필요한 연산 제거
// 나쁨: length를 매번 계산
for (let i = 0; i < arr.length; i++) {
// arr.length가 Opcode로 매번 실행됨
}
// 좋음: 한 번만 계산
const len = arr.length;
for (let i = 0; i < len; i++) {
// len은 레지스터에 캐싱됨
}✅ 메모리 접근 패턴
// 나쁨: 객체 속성 접근 (느림)
for (let i = 0; i < 1000000; i++) {
obj.prop += 1; // 매번 해시테이블 조회
}
// 좋음: 지역 변수 사용 (빠름)
let temp = obj.prop;
for (let i = 0; i < 1000000; i++) {
temp += 1; // 레지스터에서 직접 연산
}
obj.prop = temp;3️⃣ V8 엔진의 자동 최적화 (JIT와의 연결)
- V8이 하는 최적화
function add(a, b) {
return a + b;
}
// 처음 실행: 인터프리터
add(1, 2);
add(3, 4);
add(5, 6);
// V8이 관찰: "항상 숫자네?"
// TurboFan 컴파일러가 최적화
// 최적화된 기계어 (의사 코드)
// LOAD R1, [a]
// LOAD R2, [b]
// ADD R3, R1, R2 ← 타입 체크 제거!
// RETURN R3하지만 타입이 바뀌면?
add(1, 2); // 최적화됨
add(3, 4); // 최적화 버전 사용
add("hello", 5); // 타입 변경! → Deoptimization
// 다시 인터프리터로 돌아감👉 개발자가 도와줄 수 있는 방법
// 나쁨: 타입이 계속 바뀜
function process(x) {
return x + 1;
}
process(5); // 숫자
process("hello"); // 문자열 → 최적화 실패
// 좋음: 타입이 일정함
function processNumber(x) {
return x + 1;
}
function processString(x) {
return x + "!";
}🎯 핵심 정리
- 명령어 = 비용
JavaScript 한 줄 = 수십~수백 개의 CPU 명령어
명령어 줄이기 = 실행 시간 단축 = 성능 향상
- 함수 호출은 비싸다
함수 호출 = 스택 프레임 생성 + Operand 저장 + 점프
재귀 = 스택 누적 → Stack Overflow 위험
- 작은 최적화도 누적되면 크다
sum += x (4 명령어) vs sum = sum + x (5 명령어)
100만 번 반복 → 1억 명령어 차이
대규모 서버 → 비용 20% 절감 가능
- 최적화 우선순위
1순위: 알고리즘 (O(n) vs O(n²))
2순위: 불필요한 연산 제거
3순위: 메모리 접근 패턴
4순위: 미세 최적화 (+= vs = +)
- V8과 협력하기
- 타입 일관성 유지 (최적화 유지)
- Hot Path 코드 집중 최적화
- 프로파일링으로 병목 찾기